两篇微博引发的思考
前段时间微博上注意到叔度,发了两篇关于面试的微博:
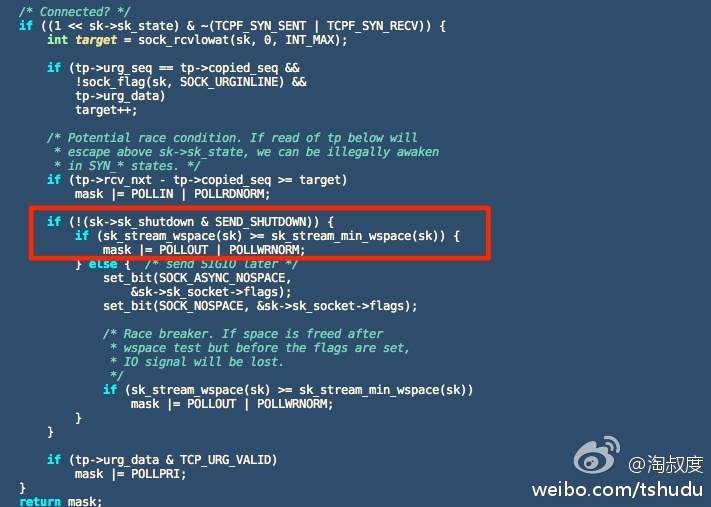
一些小伙伴们写网络程序的一个坏习惯是连接建立后就挂上可写事件,这是很浪费的。正确的方法是先写,写不下去才挂上可写事件。另外,可写事件其实不是事件,它只是判断发送缓冲区是否还有空间,它是被底层的TCP事件给附带上来的。附图是Linux内核源码实现。
对于非阻塞的connect,返回EINPROGRESS之后要加fd到epoll的可写事件监视集合里面,等fd可写了之后记得要调用getsockopt判断SOL_SOCKET的SO_ERROR值是否为0!非0表示连接失败。
EPOLL使用
- ET only noblocking mode
处理方式:
- 读:只要可读,就一直读,直到返回0,或者 errno = EAGAIN
- 写:只要可写,就一直写,直到数据发送完,或者 errno = EAGAIN
- LT
分析:一旦建立链接就挂可写事件(noblocking mode):
- 若在ET模式下,其实还好,相比与LT模式。哈..
- 若在LT模式下,将会不停的触发!
如何做呢。正如叔度所说,先写,直到errno=EAGIN。挂载写事件,在epoll的驱动下完成全部内容的发送。当然nginx就是这么实现的。ngx_http_write,但是LT模式下,需不需要触发后从epoll中移出此可写事件呢。
问题:
nginx使用了何种触发方式?
listen的socket用的水平触发,而accept之后的端口使用的是边沿触发。为何这么麻烦呢?
1.listen的fd使用水平触发是因为害怕丢失链接;其实使用边沿触发也有解决办法:用while循环抱住accept调用,处理完TCP就绪队列中的所有连接后再退出循环。nginx有个配置选项:multi_accept,这是为啥?莫非是为了减少epoll_wait的系统调用?
2.使用ET可以有效的减少系统调用,但是ET,LT哪种更高效,貌似没用确切的结论。ET理论上可以比LT少带来一些系统调用,所以更省一些。具体的性能提高有多少,要看应用场景。不过绝大部分场景下,LT是足够的。
nginx水平触发代码如下:若nginx配置accept_mutex on时会调用如下函数
static ngx_int_t
ngx_enable_accept_events(ngx_cycle_t *cycle)
{
ngx_uint_t i;
ngx_listening_t *ls;
ngx_connection_t *c;
ls = cycle->listening.elts;
for (i = 0; i < cycle->listening.nelts; i++) {
c = ls[i].connection;
if (c->read->active) {
continue;
}
if (ngx_event_flags & NGX_USE_RTSIG_EVENT) {
if (ngx_add_conn(c) == NGX_ERROR) {
return NGX_ERROR;
}
} else {
if (ngx_add_event(c->read, NGX_READ_EVENT, 0) == NGX_ERROR) {
return NGX_ERROR;
}
}
}
return NGX_OK;
}一道面试题目: 使用Linux epoll模型,水平触发模式;当socket可写时,会不停的触发socket可写的事件,如何处理?
另一个问题:
直接看man 2 connect:
EINPROGRESS
The socket is non-blocking and the connection cannot be completed immediately. It is possible to select(2) or poll(2) for completion by selecting the socket for writing.After select(2) indicates writability, use getsockopt(2) to read the SO_ERROR option at level SOL_SOCKET to determine whether connect() completed successfully (SO_ERROR is zero) or unsuccessfully (SO_ERROR is one of the usual error codes listed here, explaining the reason for the failure).
但是为什么呢?不成功也会返回可写事件?这是必须的。不管成功或者失败,总需要给client端一个交代吧。
缓冲区
发送缓冲区(send buffer)
ex:发送一个14M的buffer–公司客户端某些同事,就是在nonblocking模式下发送14m文件的,而且他就send了一次。
1.block模式下,等待所有的buffer发送完后返回。block方式有可能返回小于buffer长度的值么?嗯,是的。在对方异常关闭或超时是会造成返回小于buffer长度的值如果对端返回rst时,继续写的话会产生SIGPIPE,这里需要特别注意,因为sigpipe默认处理是关闭进程!一般情况下,需要捕捉此信号;
2.noblocking模式下,若返回值为-1,errno=EAGAIN,则加入侦听;若返回值为大于0,则循环继续发送;
这个要说下nginx:
当然如果发送文件的话,nginx用的sendfile。
sendfile的好处是啥呢?减少copy次数。
这里必须要解释下copy为啥费时费力的:
copy一般情况下需要cpu,寄存器,一次只能copy 32bit,所以一个指令周期只能copy 32bit。所以出现了DMA,sendbuf,splice,cow等技术。nginx在upstream也做了优化。具体见:代理服务器中的内容防拷贝技术 ,也因此有了面试题目:
void memcpy(void *src,void *dst)
{
//如何实现更快...
//可以转为int *类型这个,一个指令周期就可以最大化的copy
}也就有了内存对齐。写到这里忽然想起另一个无关的东西:RingBuffer的实现,里面有个cache_line_padding 跟这个有异曲同工之妙,不过跟copy无关是关于无锁队列的。可是sendfile就好了么?nginx还有更深层的优化。正常情况下,nginx是设置tcp_nodelay;但是在sendfile时,会设置tcp_cork。
在传输文件时,我们可以做那些优化呢?
接收缓冲区(read buffer) epoll返回可读事件,调用recv返回0,则表示对端关闭。对端close,若拔网线呢?keepalive情况下会触发可读事件。